
About
Cornelius Vanderbilt Scholar at Vanderbilt University | Computer Science and Mathematics Majors | Data Science and Neuroscience Minors. Interested in artificial intelligence and its applications, logic problems, and data pipelines.
Research Interests
Current Research Projects
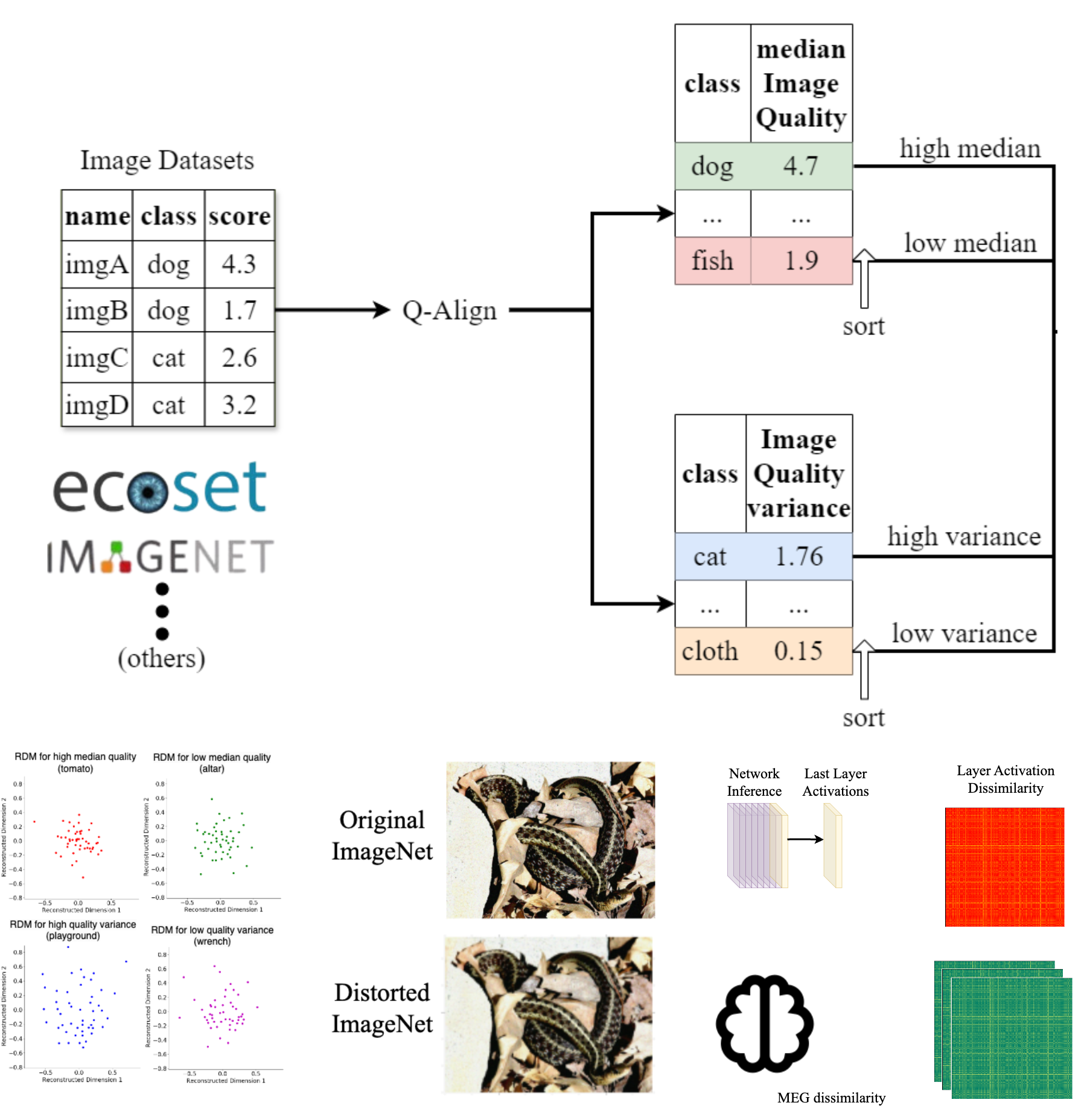
Image Quality and Neural Networks
Training data encompasses inherent biases, and it is often not immediately clear what constitutes good or bad training data with respect to these biases. Among such biases is image quality for visual datasets, which is multifaceted, involving aspects such as blur, noise, and resolution. In this study, we investigate how different aspects of image quality and its variance within training datasets affect neural network performance and their alignment with human neural representations. By analyzing large-scale image datasets using advanced image quality metrics, we categorize images based on diverse quality factors and their variances.

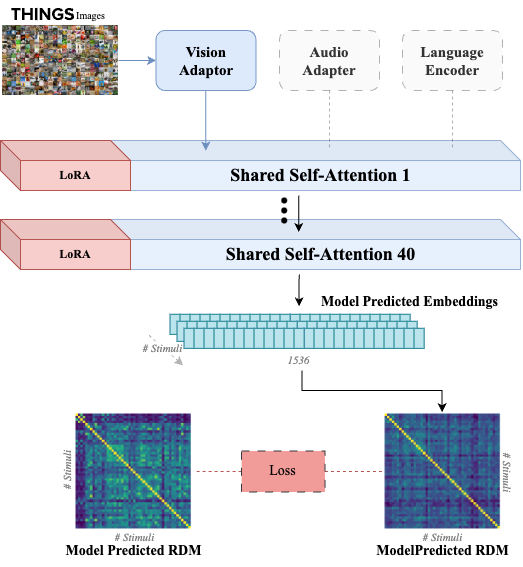
Personalized Brain-Inspired AI Models (CLIP-Human Based Analysis)
We introduced personalized brain-inspired AI models by integrating human behavioral embeddings and neural data to better align artificial intelligence with cognitive processes. The study fine-tunes multimodal state-of-the-art AI model (CLIP) in a stepwise manner—first using large-scale behavioral decisions, then group-level neural data, and finally, participant-specific neural dynamics—enhancing both behavioral and neural alignment. The results demonstrate the potential for individualized AI systems, capable of capturing unique neural representations, with applications spanning medicine, cognitive research, and human-computer interfaces.
Crossmodal Human Enhancement of Multimodal AI
Human perception is inherently multisensory, with sensory modalities influencing one another. To develop more human-like multimodal AI models, it is essential to design systems that not only process multiple sensory inputs but also reflect their interconnections. In this study, we investigate the cross-modal interactions between vision and audition in large multimodal transformer models. Additionally, we fine-tune the visual processing of a state-of-the-art multimodal model using human visual behavioral embeddings